数学
线性代数
1.正定矩阵和半正定矩阵
【定义1】给定一个大小为$n\times n$的实对称矩阵$A$,若对于任意长度为$n$的非零向量$\boldsymbol{x}$,有$\boldsymbol{x}^TA\boldsymbol{x}>0$恒成立,则矩阵$A$是一个正定矩阵。
【定义2】给定一个大小为$n\times n$的实对称矩阵$A$,若对于任意长度为$n$的向量$\boldsymbol{x}$,有$\boldsymbol{x}^TA\boldsymbol{x}\geq0$恒成立,则矩阵$A$是一个半正定矩阵。
这个其实就是说一个向量经过正定矩阵这一线性变换之后的到的新的向量与原向量的夹角不会超过$90^{o}$。
判断一个矩阵A是否为正定矩阵有两种方法:
- 求出A的所有特征值。若A的特征值均为正数,则A是正定的;若A的特征值均为负数,则A为负定的。
- 计算A的各阶顺序主子式。若A的各阶顺序主子式均大于零,则A是正定的;若A的各阶主子式中,奇数阶主子式为负,偶数阶为正,则A为负定的。
矩阵正定性的性质:
- 正定矩阵的特征值都是正数。
- 正定矩阵的所有子行列式都是正数。
- 若A为n阶正定矩阵,则A为n阶可逆矩阵。
2.正交矩阵的定义和性质
定义:A是一个方阵,且$A^TA=E$,则称A为正交矩阵。
性质:
- $det(A^TA)=det(E)=1$,得到$det(A)=\pm 1$
- A和B都是正交阵,则AB也是正交阵
- 一组标准正交基(两两正交且模长为1的向量组)下的正交变换可以用正交矩阵表示。正交变换不改变向量的模长和向量间的夹角。
正交变换$T$满足:$|T\alpha|=|\alpha|$。
概率论
1.独立和互斥
独立说的是$P(A|B)=P(A)$,即$P(AB)=P(A)P(B)$,就是说A发生的概率不受B的影响。
互斥说的是$P(AB)=0$,即A和B不能同时发生。
显然,当$P(A)>0, P(B)>0$时,独立不互斥,互斥不独立。
2.大数定理
切比雪夫不等式:$P\left \{ |X - EX| \ge \varepsilon \right \} \le \frac{DX}{\varepsilon ^{2} }$
辛钦大数定理:设$X_1,X_2…X_n$
是独立同分布的随机变量序列,且具有数学期望$EX_k=μ,k=1,2,3…$。则对于$∀ε>0$,有$\lim_{n \to +\infty} P\left \{ | \frac{1}{n}\sum_{k=1}^{n}X_{k} - \mu | < \varepsilon \right \} = 1$,均值依概率收敛于期望。(对方差没有要求)切比雪夫大数定律:设$X_1,X_2…X_n$是不相关的随机变量序列,且期望$E_i$和方差$D_i$都存在,方差有界$D_i\le M$,则对于$∀ε>0$,有$\lim_{n \to +\infty} P\left \{ | \frac{1}{n}\sum_{i=1}^{n}X_{i} - \frac{1}{n}\sum_{i=1}^{n}EX_i | < \varepsilon \right \} = 1$,均值依概率收敛于期望的均值。
切比雪夫大数定律:设$X_1,X_2…X_n$是相互独立的随机变量序列,且具有相同的期望$\mu$和方差$\sigma ^ 2$,则对于$∀ε>0$,有$\lim_{n \to +\infty} P\left \{ | \frac{1}{n}\sum_{i=1}^{n}X_{i} - \mu | < \varepsilon \right \} = 1$,均值依概率收敛于期望。
其实就是n越来越大,样本均值趋近于期望,频率趋近于概率。
3.贝叶斯公式
$P(A|B)= \frac{P(A)P(B|A)}{P(B)}$
$P(A_i|B)= \frac{P(A_i)P(B|A_i)}{\sum_{k=1}^{n}P(A_k)P(B|A_k)}$
第二个公式下边用了一个全概率公式$(A_1,A_2,…,A_n)$为完备事件集。
举个栗子,就是说如果我们知道患各种病的情况下发烧的概率,我们就可以推断出发烧的情况下患各种病的概率。
4.中心极限定理
$X_1, X_2, …, X_n…$独立同分布,$EX_i=\mu, DX_i=\sigma^2, 0<\sigma^2<+\infty$,则$\lim_{n \to \infty} P(\frac{\Sigma_{i=1}^nX_i-n\mu}{\sqrt{n}\sigma }\le x)=\Phi_0(x)$。
大量独立同分布的随机变量的和服从正态分布。
离散数学
1.群、环、域
代数主要研究的是运算规则。一门代数, 其实都是从某种具体的运算体系中抽象出一些基本规则,建立一个公理体系,然后在这基础上进行研究。一个集合再加上一套运算规则,就构成一个代数结构。
他三都是抽象代数,就是说把数字抽象成一个集合,集合里的元素不管是啥。然后把具体的加、减、乘、除之类的二元运算抽象成运算,不管运算具体干啥。
表示就表示为代数结构(R, *),R是对象集合,*是集合上的二元运算。如果代数结构满足了某些性质,就给他们起相应的名字。
群: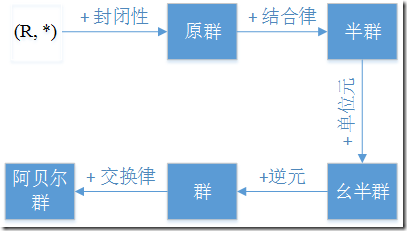
环和域: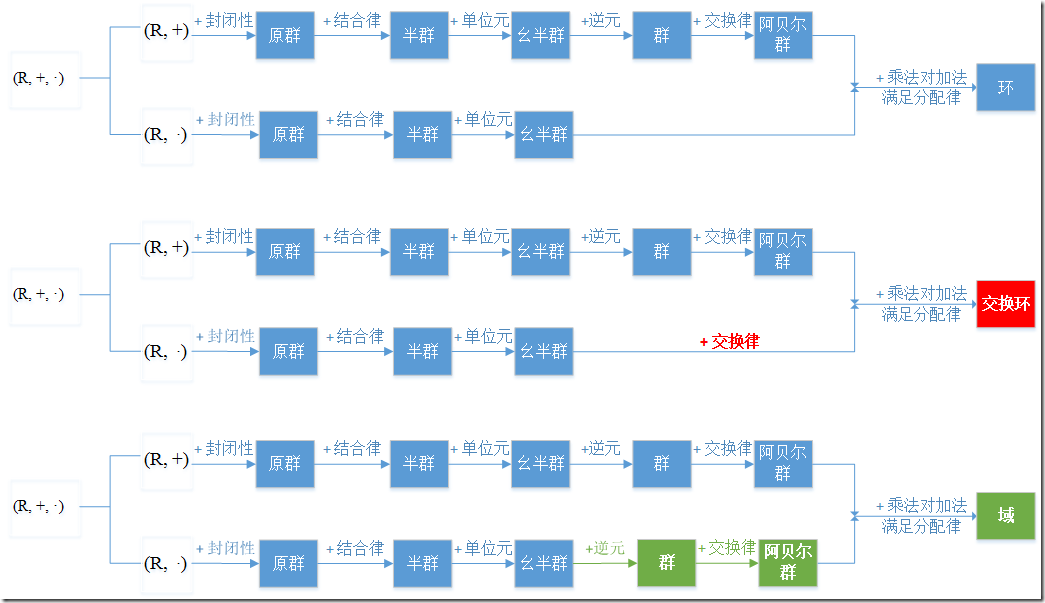
2.命题逻辑与谓词逻辑
命题逻辑具有局限性,比如苏格拉底三段论就没法表示。
在命题逻辑中,命题是具有真假意义的陈述句。从语法上分析,一个陈述句由主语和谓语两部分组成。在谓词逻辑中,为揭示命题内部结构及其不同命题的内部结构关系,对命题进行分析,并且把主语称为个体或客体,把谓语称为谓词。
在命题逻辑中,一个可以判断真假的陈述句就是研究的最小单元;谓词逻辑是对命题逻辑更进一步的细分,将一个陈述句分为客体和谓词。
3.幂集
集合的集合:$P(A)=\left \{x|x\subseteq A \right \}$
估计叫做幂集是因为里面的元素个数正好是A集合元素个数的2的幂次。
4.关系
定义 如果一个集合满足以下条件之一:
- 集合非空, 且它的元素都是有序对
- 集合是空集
则称该集合为一个二元关系, 简称为关系,记作R.
如$\lt x,y\gt$∈R, 可记作xRy;
设A,B为集合,A×B的任何子集所定义的二元
关系叫做从A到B的二元关系, 当A=B时则叫做 A上
的二元关系.
5.集合的划分
集合的划分指的是把集合划分成若干个小的集合,这些小集合并起来等于原来的大集合,且小集合两两之间没有交集。这些小集合就叫做原来集合的一个划分。
等价关系的商集就是一个划分。
6.欧拉图和哈密尔顿图
这里要区分欧拉路径和欧拉回路。欧拉回路是个圈,欧拉路径是个环或者链。
连通的无向图$G$有欧拉路径的充要条件是:$G$中奇顶点(连接的边数量为奇数的顶点)的数目等于0或者2。
连通的无向图$G$是欧拉环(存在欧拉回路)的充要条件是:
$G$中每个顶点的度都是偶数。
哈密顿路径和哈密顿回路也是类似的。回路是圈,路径是环或链。哈密顿回路去掉一条边就是哈密顿路径,但是哈密顿路径加上一条边不一定能变成哈密顿回路。
找哈密顿路径是个NP问题。
具有欧拉回路的图叫欧拉图;具有哈密顿回路的图叫哈密顿图。只有欧拉路径但没有欧拉回路的图叫半欧拉图;只有哈密顿路径但没有哈密顿回路的图叫半哈密顿图。
高数
1.连续和一致连续
连续:$\lim_{x \to x_0}f(x)=f(x_0)$。即$\forall \varepsilon > 0, \exists \delta > 0, \forall x\in D_f, 0 < |x-x_0| < \delta, 使得|f(x)-f(x_0)|<\varepsilon$。
一致连续:$\forall \varepsilon > 0, \exists \delta > 0, \forall x_1, x_2\in D_f, |x_1-x_2| < \delta, 都有|f(x_1)-f(x_2)|<\varepsilon$。
一致连续的函数不能很陡峭。
2.最小二乘法
就是用几个线性无关的函数的线性组合来对样本进行拟合。目标就是让预测值和实际值的差的平方和最小。求每个函数前边的系数。具体解法就是对每个参数求偏导,让偏导数等于零。
$h_\theta(x)=\theta_0+\theta_1x+\theta_2x^2+…+\theta_nx^n+…$
目标是让$\Sigma_{i=1}^{n}(y_i-h_\theta(x_i))^2$最小。
3.可微和可导的关系
对于一元函数来说,可微$\Leftrightarrow $可导$\Rightarrow$连续$\Rightarrow$可积。
对于多元函数来说,函数在一点可微$\Leftrightarrow$函数的所有偏导数在该点存在并连续$\Rightarrow$连续$\Rightarrow$可积。
导数和微分本质是两种东西,前者是函数在某个方向上的变化率,后者是映射的局部线性近似。ref
专业课
数据结构
1.几个排序算法介绍,时空复杂度,稳定性咋样?
操作系统
计组
1.USB接鼠标/键盘有什么区别?
北航面试的问题,这是啥意思鸭。我个人理解的是对于键盘来说,按键的到来随时间是离散的;而对于鼠标来说,其位置移动随时间是连续的。因此如果接入键盘,按下一个按键就发起一个中断即可,如果接入鼠标,则需要将鼠标的位置移动先缓存到缓冲区中,缓冲区满了再统一发起中断?
2.计算机是如何启动的?
- BIOS: 计算机通电后,首先读取并执行BIOS(基本输入输出系统)程序。BIOS程序首先进行硬件自检,检查硬件是否能满足运行的基本条件。BIOS感觉和AM点类似?
- 启动程序: BIOS寻找MBR主引导记录,将找到的引导程序加载至内存,并将控制权交给引导程序。引导程序把操作系统从硬盘读入到内存。
- 控制权交给操作系统,OS创建一个init进程,其pid为1,是所有进程的祖先。然后init进程加载系统的各个模块。
3.体系结构和组成原理的区别
计算机体系结构是程序员眼中的计算机。程序员眼中的计算机有指令集、数据类型、寻址技术等。只要两个计算机指令集、数据类型、寻址类型等相等,就说这两个计算机体系结构相同。计算机组成是体系结构的具体实现形式。一个计算机是否具有乘法指令的功能,这是结构问题,而用什么方式实现乘法,就是组成问题。实现乘法可以用一个专门的乘法电路,也可以用连续相加的加法电路来实现,这两者的区别就是组成问题。
举个例子:大概就是x86架构是体系结构,如何实现x86架构是组成原理。
计网
1.各个层的作用
- 应用层:满足用户应用需求。
- 传输层:维护端到端连接的可靠性,复用和分用。
- 网络层:路由与转发。
- 链路层:维护点到点连接的可靠性,编码解码,逻辑链路层+介质访问控制层。
- 物理层:信息传输。
2.输入网址并按下enter后发生的事情。
- 俯视角度:
- DNS找到目标主机ip:网址是url,是人看的懂得形式,但是计算机在网络中是通过ip地址来标识主机的。所以首先需要通过DNS来把域名解析为ip地址。具体过程为,首先查找本机的DNS缓存如果找到了直接解析,如果没有找到就向本地域名服务器发起DNS请求。本地域名服务器接收到DNS请求后,首先查找自己的缓存有没有对应的记录,如果找到了直接返回给客户机即可。如果没有找到,则首先向根域名服务器发起DNS请求,根域名服务器返回对应的顶级域名服务器的ip地址;然后本地域名服务器再向顶级域名服务器发起DNS请求,顶级域名服务器返回对应域名的权威服务器的ip地址;然后本地域名服务器向权威域名服务器发起请求,权威域名服务器返回所请求的域名对应的ip地址。最后,本地域名服务器将得到的ip地址返回给客户机,并在自己机器里缓存对应的域名资源记录。请求本地域名服务器的过程是递归式的,本地域名服务器向其他域名服务器请求解析的过程是迭代式的。
- TCP三次握手建立连接:Web浏览器使用http应用层协议,http协议基于TCP传输层协议。因此,浏览器得到服务器的ip地址后首先要和服务器通过三次握手建立TCP连接。这个过程很简单,主要就是用于同步TCP的序列号之类的。就是SYN、SYN+ACK、ACK这三次握手,具体不写了。
- 客户端服务器通过http协议传输数据:建立TCP连接之后,客户端向服务器发送http请求报文,然后服务器收到请求报文后对其进行解析和处理,并返回响应报文。客户端接收到响应报文后,根据报文的内容将页面渲染出来,如果页面中引用了其他的对象,就需要再次发起http请求。报文格式也比较固定,不写了。
- TCP四次挥手断开连接:客户端和服务器完成通信后,需要通过四次挥手断开TCP连接。然后这里的一个问题就是一方发送FIN后表示他不会发送数据了,但是另一方此时还是可以发送数据的。
- 平视角度:
- 应用层调用socket接口,借助传输层传输数据。
- 传输层得到应用层要传输的数据和目标ip目标端口之后,封装一个传输层数据单元(忘了叫啥名字了,数据段?),头部里面存储的有源端口、目标端口、协议相关的一些东西。然后传输层将数据单元传给ip层。这里端口起到分用和复用的作用,就是说一个ip上有多个端口,就类似于一栋楼里面有多个住户一样。
- ip层得到传出层传下来的服务数据单元和目标ip之后,封装一个ip层数据单元,头部里面有源ip、目标ip、ttl、分片的字节偏移啥的。然后ip层会查自己的路由表,找到要从哪个端口把数据发出去。这个过程就是转发。查表之后把数据报传给链路层。生成路由表的过程是路由,需要路由算法的支持,路由算法主要有两种,一个是链路状态算法(dijkstra的思想),一个是距离矢量算法(dp的思想)。
- 链路层对ip层的数据进行进一步的封装和发送。这里涉及到需要知道目标端口的问题,因为链路层只知道目标ip,不知道目标端口,它就需要首先通过目标ip(指的是下一跳的ip)找到目标端口,具体使用ARP协议。大致就是先广播一下,询问目标ip的主机的端口MAC地址(标识端口)是啥,然后目标ip的主机收到报文后就会返回给询问MAC地址的主机一个报文,告诉他自己的MAC地址是啥。这样就可以找到目标ip的端口了,最后再把这个ip到MAC的映射缓存一下,之后用的时候直接查表即可。找到目标MAC后,链路层对数据报进行封装,封装成帧,然后把帧通过物理层发送出去就行了。
- 物理层不太会,大概就是传输信号?
3.为什么IP是面向无连接的协议。
- 面向连接的协议的连接处理过程较为复杂,且容易降低处理速度。
- 不利于提供不同类型的服务,如一些即时视频等应用,使用面向连接的协议会影响服务的质量。网络分层可以很好的提供个性化的定制服务。
IP协议就是尽力而为交付。
4.路由算法
- 链路状态算法:首先得到整个网络的拓扑结构,然后在这个图上执行dikstra算法,计算出当前点到其他节点的最短路。代表协议是OSPF协议。
- 距离矢量算法:维护一个当前节点到其他各个节点的距离向量,以及当前节点的每个邻居到其他各个节点的距离向量。当自己的距离向量发生改变时,将这个距离向量通告给邻居节点;当接收到来自邻居节点的新的距离向量时,更新自己的距离向量。
毒性逆转就是说,如果一个节点通过另一个邻居节点到目标节点路径最短,这个节点通告给该邻居节点的距离向量中,该节点到目标节点的最短距离为无穷。主要是为了解决坏消息传递的慢的问题。代表协议是RIP协议。
数据库
1.数据库的第一第二第三范式
- 1NF:数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
- 2NF:非主属性必须完全依赖于主键,要求数据库表中的每个实例或记录必须可以被唯一地区分。
- 3NF:在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖,则符合第三范式。简而言之,第三范式就是属性不依赖于其它非主属性。
- BCNF:任何主属性不能对主键子集依赖。
一般来说,数据库只需满足第三范式(3NF)就行了。
编译原理
1.从代码到可执行程序的步骤
- 预处理:主要是处理注释和宏定义。
- 编译:把预处理后的代码编译为目标平台的汇编代码。
- 词法分析:将字符流识别为单词流。
- 语法分析:识别语句的语法结构,构建语法树。
- 语义分析:类型检查,类型转换之类的。
- 中间代码生成:将语法树翻译为中间代码。
- 中间代码优化:优化中间代码。
- 目标代码生成:将中间代码翻译为目标代码。
- 目标代码优化:优化目标代码。
- 汇编:对于编译生成的汇编代码,汇编器将其翻译为二进制可重定位文件。
- 链接:文件中可能引用外部符号,链接主要就是处理这些符号引用,把多个可重定位文件合成一个可执行文件,并计算符号的地址之类的。
英文
自我介绍
Good morning/afternoon/evening professors. I am greatly honored to be here for this interview.
// 大致介绍背景
My name is XuWenBin, from XinXiang, HeNan Province, and I am studying computer science at NanKai University.
// 介绍高中情况,省一
Since high school, I have had a strong interest in computer science and started to learn programming and algorithm knowledge. And I won the provincial first prize in NOIP.
// 介绍大学成绩和奖项
In terms of my schoolwork in college, I love learning very much and have a solid professional knowledge base. I worked hard and got good grades in most of my courses, ranking 10th out of 163.And I was awarded an Academic Excellence Scholarship for outstanding grades. As for language, besides passing CET-4 and CET-6 with decent scores, I also learned Japanese and passed the CJT-4.
// 介绍项目
What’s more, I have strong practical ability and took part in many projects. For example, I wrote a compiler for a subset of the C language with my teammates from scratch this summer and won second prize of Bi Sheng Cup. And I implemented a reliable transmission protocol that supports piplining and congestion control at the application layer based on the UDP protocol.
// 介绍研究兴趣和未来规划
In the past three years, I have developed a strong interest in the field of computer systems. In the future, I’m willing to do relevant scientific research work in university.
This concludes my introduction. Thanks for your attention.
介绍家乡
I come from Henan province. There are many people in Henan province. And Henan people are very able to bear hardships. What’s more, we don’t really steal manhole covers. As for food, I think HuiMian is the most famous and delicious food of Henan. There are also many places and interests in Henan, such as Longmen Grottoes, white horse temple, Qingming Shanghe Garden and so on.