zram
斌斌陪你读之——zram zram是啥 首先,zram是啥,zram是linux使用内存抽象出来的一个块设备。zram常用作交换设备使用,类似于一个ssd。zram会对写入其中的页进行压缩处理,从而起到节省内存同时提高程序启动速率的效果。对于没有交换设备或者磁盘读写次数有限的情况,zram可以起到比较好的加速效果。(zram wiki) 。
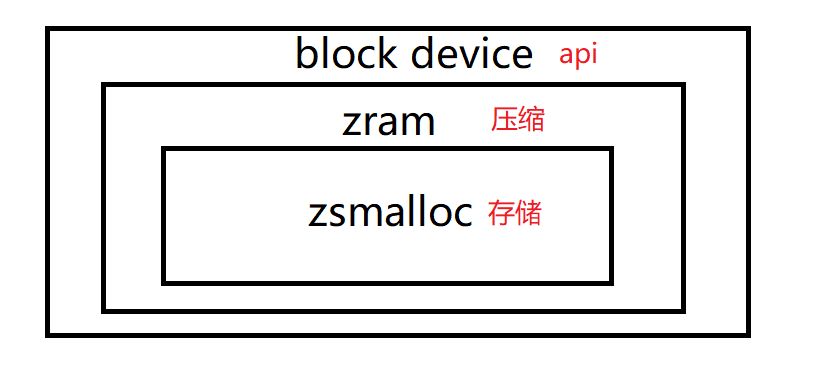
zram大体框架
如上图所示(不太会画图,权当没有图),zram向外部呈现一个block device的抽象,向外界提供块设备的接口;内部,由于zram使用的是物理内存,需要一个内存分配器,这里zram使用zsmalloc内存分配器;而zram则负责对用户向其写入的数据进行压缩处理,将压缩后的数据存储到zsmalloc分配的内存中。其实压缩这一部分也不是zram做的,压缩主要通过zcomp部分来进行,zram只是调用了zcomp部分的一些函数。感觉zram主要就是写了一个驱动,然后其他的功能大部分是用的linux中现成的代码做的。
在CSDN上找到了一篇关于zram的写的比较好的博客,可以先看看有一个较为宏观的了解:zRAM内存压缩技术分析及优化方向
代码阅读 下面,对linux中zram部分的源码进行大致地阅读。内核版本为linux6.1 。
数据结构 zram结构体(zram类) 下方代码为zram类的实现,对其中的成员变量的含义进行解释。
table: 是一个zram_table_entry数组,数组的每一项对应了zram中的一页,存储了该页的元数据信息。
mem_pool: 前文提到zram使用zsmalloc进行内存的分配和管理。这个mem_pool就相当于zsmalloc给zram分配的一个内存池,zram可以向其读写数据。
comp: 这个是zram的压缩模块,zram对数据压缩和解压时通过comp的一些函数进行。
disk: linux内核中,用gendisk结构体表示一个磁盘设备或分区。其中存储了一些关于zram的信息,如设备号啥的,同时disk还指向了zram处理I/O的一些API,这个就相当于zram对外部提供的一个块设备抽象。一个参考blog
init_lock: 一个读写锁,就是可以有很多人同时读,但只能有一个人写的那种锁。
limit_pages: 这个就是zram这个块设备最多有几页,也是table数组的最大长度。
stats: statistics的缩写?这个变量存储了zram执行过程中的一些统计信息。
disksize: 整个zram磁盘有多大,字节为单位。
comperssor: 压缩算法的名字。
之后的后边再写,别忘了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct zram { struct zram_table_entry *table ; struct zs_pool *mem_pool ; struct zcomp *comp ; struct gendisk *disk ; struct rw_semaphore init_lock ; unsigned long limit_pages; struct zram_stats stats ; u64 disksize; char compressor[CRYPTO_MAX_ALG_NAME]; bool claim; #ifdef CONFIG_ZRAM_WRITEBACK struct file *backing_dev ; spinlock_t wb_limit_lock; bool wb_limit_enable; u64 bd_wb_limit; struct block_device *bdev ; unsigned long *bitmap; unsigned long nr_pages; #endif #ifdef CONFIG_ZRAM_MEMORY_TRACKING struct dentry *debugfs_dir ; #endif };
zram_table_entry结构体 描述了zram中一个页的元数据。
handle: 当前页在mem_pool中的句柄。注意,这个handle不指向具体的地址,而是在需要的时候调用一个函数,将handle对应的内容映射到一个地址处,数据访问完之后再撤销这个映射。
element: 如果当前页被相同的元素填充,element存储这个元素的值。此外,如果zram中的一个页被写回到了磁盘中,element会存储该页在磁盘中的句柄。
flags: zram为了节省内存空间,这个变量的低位存储当前页中存储的对象的大小,高位存储当前页的状态。
ac_time: 不知道干嘛的,看注释像是track计时用的。
1 2 3 4 5 6 7 8 9 10 struct zram_table_entry { union { unsigned long handle; unsigned long element; }; unsigned long flags; #ifdef CONFIG_ZRAM_MEMORY_TRACKING ktime_t ac_time; #endif };
zram_pageflags枚举 这个枚举就是上述zram_table_entry结构体中flags变量高位的含义,注释给的比较清楚了,这里不做过多说明。其中ZRAM_LOCK这一位比较有意思,这一位充当了一个自旋锁的作用,对该页加锁时将该位置1,解锁时将该位清零。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #define ZRAM_FLAG_SHIFT (PAGE_SHIFT + 1) enum zram_pageflags { ZRAM_LOCK = ZRAM_FLAG_SHIFT, ZRAM_SAME, ZRAM_WB, ZRAM_UNDER_WB, ZRAM_HUGE, ZRAM_IDLE, __NR_ZRAM_PAGEFLAGS, };
zram_stats结构体 这个结构体存储了zram运行过程中的一些统计信息,注释给的也比较清楚。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct zram_stats { atomic64_t compr_data_size; atomic64_t num_reads; atomic64_t num_writes; atomic64_t failed_reads; atomic64_t failed_writes; atomic64_t invalid_io; atomic64_t notify_free; atomic64_t same_pages; atomic64_t huge_pages; atomic64_t pages_stored; atomic_long_t max_used_pages; atomic64_t writestall; atomic64_t miss_free; #ifdef CONFIG_ZRAM_WRITEBACK atomic64_t bd_count; atomic64_t bd_reads; atomic64_t bd_writes; #endif };
一些宏
PAGE_SHIFT: 一个页几位,12位。
SECTOR_SHIFT: 一个扇区几位,linux中好像都是9,即一个扇区512字节。
SECTORS_PER_PAGE_SHIFT: 一页中的扇区号占几位,12-9=3,即一个页中有8个扇区。
SECTORS_PER_PAGE: 一个页中的扇区数。
ZRAM_LOGICAL_BLOCK_SHIFT: zram逻辑块占几位,这里是12,一页。
ZRAM_LOGICAL_BLOCK_SIZE: zram逻辑块大小,4K。
ZRAM_SECTOR_PER_LOGICAL_BLOCK: zram中每个逻辑块中有几个扇区,8个。
这里涉及到了扇区和块的一些定义,网上的解释挺多的。比如这个 ,请自行查阅。
1 2 3 4 5 6 #define SECTORS_PER_PAGE_SHIFT (PAGE_SHIFT - SECTOR_SHIFT) #define SECTORS_PER_PAGE (1 << SECTORS_PER_PAGE_SHIFT) #define ZRAM_LOGICAL_BLOCK_SHIFT 12 #define ZRAM_LOGICAL_BLOCK_SIZE (1 << ZRAM_LOGICAL_BLOCK_SHIFT) #define ZRAM_SECTOR_PER_LOGICAL_BLOCK \ (1 << (ZRAM_LOGICAL_BLOCK_SHIFT - SECTOR_SHIFT))
具体代码 看具体代码之前可以先看看linux驱动程序怎么编写的,以及一些关于设备I/O方面的知识。这里有一些参考网站:
设备初始化 zram_init 初始化函数为zram_init函数。函数首先调用cpuhp_setup_state_multi函数设置了一下cpu热插拔的回调函数(cpu热插拔我还没怎么看)。然后调用class_register注册一个zram_control_class类(这个类好像是用于文件系统相关的,还没怎么看)。然后调用register_blkdev注册了一个块设备,叫做”zram”。虽然注册好了,但是实际上管理zram的数据结构还都没咋建立起来,然后继续调用zram_add来分配和初始化实际的zram设备。如果上述过程中哪一步出错了,就会转去执行destory_devices函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static int __init zram_init (void ) { int ret; BUILD_BUG_ON(__NR_ZRAM_PAGEFLAGS > BITS_PER_LONG); ret = cpuhp_setup_state_multi(CPUHP_ZCOMP_PREPARE, "block/zram:prepare" , zcomp_cpu_up_prepare, zcomp_cpu_dead); if (ret < 0 ) return ret; ret = class_register(&zram_control_class); if (ret) { pr_err("Unable to register zram-control class\n" ); cpuhp_remove_multi_state(CPUHP_ZCOMP_PREPARE); return ret; } zram_debugfs_create(); zram_major = register_blkdev(0 , "zram" ); if (zram_major <= 0 ) { pr_err("Unable to get major number\n" ); class_unregister(&zram_control_class); cpuhp_remove_multi_state(CPUHP_ZCOMP_PREPARE); return -EBUSY; } while (num_devices != 0 ) { mutex_lock(&zram_index_mutex); ret = zram_add(); mutex_unlock(&zram_index_mutex); if (ret < 0 ) goto out_error; num_devices--; } return 0 ; out_error: destroy_devices(); return ret; }
zcomp_cpu_* 接下来我们看看上述代码中设置的cpu热插拔的两个回调函数zcomp_cpu_up_prepare和zcomp_cpu_dead。我目前理解的是前一个函数是cpu上线时执行的函数,后一个函数是cpu下线时执行的函数。这俩逻辑都比较简单,直接给注释了。注意其中的压缩流,压缩流需要一个压缩缓冲区和一个执行压缩的实体,创建压缩流和释放压缩流其实就是操作这两个东西。这个压缩流就是用来压缩和解压页面的东西。这里有个问题,就是为啥要从一个链表中取comp嘞,这个链表节点啥时候加进去的呢?可以看看zcomp_init函数,比较简单,这里略过。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int zcomp_cpu_up_prepare (unsigned int cpu, struct hlist_node *node) { struct zcomp *comp =struct zcomp, node); struct zcomp_strm *zstrm ; int ret; zstrm = per_cpu_ptr(comp->stream, cpu); local_lock_init(&zstrm->lock); ret = zcomp_strm_init(zstrm, comp); if (ret) pr_err("Can't allocate a compression stream\n" ); return ret; } int zcomp_cpu_dead (unsigned int cpu, struct hlist_node *node) { struct zcomp *comp =struct zcomp, node); struct zcomp_strm *zstrm ; zstrm = per_cpu_ptr(comp->stream, cpu); zcomp_strm_free(zstrm); return 0 ; }
zram_add 接下来看添加zram设备的zram_add函数,这个函数主要做的就是创建zram、gendisk结构体,然后对这些结构体中的参数进行初始化。代码首先创建了一个zram结构体,然后调用idr_alloc函数将zram结构体和一个整数关联起来,这个整数就作为该zram设备的设备号。之后初始化了一下zram中的锁。然后创建gendisk结构体,这个结构体就相当于一个磁盘类的对象,里面存储了磁盘的信息以及磁盘的操作。gendisk的major为主设备号,first_minor为第一个次设备号,minors为分区个数,可以看到这里minors为1,同时将flag设为GENHD_FL_NO_PART表示不支持分区,所以一个zram应该只有一个分区。然后比较重要的是disk->fops变量,这个fops里含有这个zram磁盘对外的操作接口。它是一个block_device_operations类型的指针,其中zram_devops是文件中定义好的一个block_device_operations结构体,里面是一些zram处理IO的函数。接下来我们还需要设置disk的请求队列的一些参数,对应的就是那一堆blk_queue*函数,每个函数具体含义网上也比较多。初始化完数据结构之后,最后调用device_add_disk函数把zram->disk注册到通用块层。然后差不多就结束了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 static int zram_add (void ) { struct zram *zram ; int ret, device_id; zram = kzalloc(sizeof (struct zram), GFP_KERNEL); if (!zram) return -ENOMEM; ret = idr_alloc(&zram_index_idr, zram, 0 , 0 , GFP_KERNEL); if (ret < 0 ) goto out_free_dev; device_id = ret; init_rwsem(&zram->init_lock); #ifdef CONFIG_ZRAM_WRITEBACK spin_lock_init(&zram->wb_limit_lock); #endif zram->disk = blk_alloc_disk(NUMA_NO_NODE); if (!zram->disk) { pr_err("Error allocating disk structure for device %d\n" , device_id); ret = -ENOMEM; goto out_free_idr; } zram->disk->major = zram_major; zram->disk->first_minor = device_id; zram->disk->minors = 1 ; zram->disk->flags |= GENHD_FL_NO_PART; zram->disk->fops = &zram_devops; zram->disk->private_data = zram; snprintf (zram->disk->disk_name, 16 , "zram%d" , device_id); set_capacity(zram->disk, 0 ); blk_queue_flag_set(QUEUE_FLAG_NONROT, zram->disk->queue ); blk_queue_flag_clear(QUEUE_FLAG_ADD_RANDOM, zram->disk->queue ); blk_queue_physical_block_size(zram->disk->queue , PAGE_SIZE); blk_queue_logical_block_size(zram->disk->queue , ZRAM_LOGICAL_BLOCK_SIZE); blk_queue_io_min(zram->disk->queue , PAGE_SIZE); blk_queue_io_opt(zram->disk->queue , PAGE_SIZE); zram->disk->queue ->limits.discard_granularity = PAGE_SIZE; blk_queue_max_discard_sectors(zram->disk->queue , UINT_MAX); if (ZRAM_LOGICAL_BLOCK_SIZE == PAGE_SIZE) blk_queue_max_write_zeroes_sectors(zram->disk->queue , UINT_MAX); blk_queue_flag_set(QUEUE_FLAG_STABLE_WRITES, zram->disk->queue ); ret = device_add_disk(NULL , zram->disk, zram_disk_groups); if (ret) goto out_cleanup_disk; strscpy(zram->compressor, default_compressor, sizeof (zram->compressor)); zram_debugfs_register(zram); pr_info("Added device: %s\n" , zram->disk->disk_name); return device_id; out_cleanup_disk: put_disk(zram->disk); out_free_idr: idr_remove(&zram_index_idr, device_id); out_free_dev: kfree(zram); return ret; }
disksize_store 前几部分相当于在内核中添加了一个zram设备驱动,最终通过zram_add函数完成了zram设备的添加,但是,在阅读上述代码的时候,我们发现,zram结构体中的一些变量如table、mem_pool、comp好像都还没有被初始化。创建zram驱动后,还需要对zram设备的大小进行配置,对应disksize_store函数。这个函数的逻辑也比较简单,首先调用memparse函数对buf进行解析,得到zram的实际大小。之后调用zram_meta_alloc函数创建zram中的table和mem_pool。然后调用zcomp_create函数创建一个压缩对象用于zram执行压缩操作。最后再给对应的变量赋一下值就行了。其中调用的zram_meta_alloc和zcomp_create都比较简单,这里先略过了,如有必要,之后会补充。这里有个问题,就是为啥要从dev里找zram呢?建议看看这个:块设备剖析之关键数据结构分析 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static ssize_t disksize_store (struct device *dev, struct device_attribute *attr, const char *buf, size_t len) { u64 disksize; struct zcomp *comp ; struct zram *zram = int err; disksize = memparse(buf, NULL ); if (!disksize) return -EINVAL; down_write(&zram->init_lock); if (init_done(zram)) { pr_info("Cannot change disksize for initialized device\n" ); err = -EBUSY; goto out_unlock; } disksize = PAGE_ALIGN(disksize); if (!zram_meta_alloc(zram, disksize)) { err = -ENOMEM; goto out_unlock; } comp = zcomp_create(zram->compressor); if (IS_ERR(comp)) { pr_err("Cannot initialise %s compressing backend\n" , zram->compressor); err = PTR_ERR(comp); goto out_free_meta; } zram->comp = comp; zram->disksize = disksize; set_capacity_and_notify(zram->disk, zram->disksize >> SECTOR_SHIFT); up_write(&zram->init_lock); return len; out_free_meta: zram_meta_free(zram, disksize); out_unlock: up_write(&zram->init_lock); return err; }
zram I/O处理 看这一部分的时候建议先大概搞清楚bio这个结构体,因为内核和zram设备之间主要依靠这个bio结构体来进行IO操作。比较推荐的是这个blog:通用块层 struct bio 详解 。也建议看看啥通用块层和request_queue之类的,虽然我搞得也不太懂。大概就是通用块层是对底层设备的一个抽象层,应该就是用gendisk结构体来抽象代表具体的块设备?然后request_queue就是一个I/O请求队列,每个gendisk都有一个这个队列,os可以向这个队列里push I/O请求,队列里的I/O请求会经过合并(比如把对相邻扇区的读写操作放在一起之类的),然后交给设备驱动处理。
zram_submit_bio zram_submit_bio这个函数用于处理所有的zram的I/O请求,好像比较早的linux版本这个函数叫zram_make_request。如下所示,函数首先调用valid_io_request函数来判断当前的I/O请求是否是一个合法的I/O请求,主要就是判断一下扇区号有没有超过zram的界限之类的。如果合法的话,就会调用__zram_make_request函数来正式处理当前的这个I/O请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 static void zram_submit_bio (struct bio *bio) { struct zram *zram = if (!valid_io_request(zram, bio->bi_iter.bi_sector, bio->bi_iter.bi_size)) { atomic64_inc(&zram->stats.invalid_io); bio_io_error(bio); return ; } __zram_make_request(zram, bio); }
valid_io_request 我们先来看一下valid_io_request函数吧。首先判断起始扇区是否对齐到每个逻辑块中的扇区数以及I/O传输的字节数是否对齐到逻辑块大小,注意这里的if判断中的unlikely,unlikely主要是用于提示编译器这个if判断结果很有可能是假,从而让编译器调整代码的位置以使代码运行的更高效,除此之外unlikely对表达式的具体结果没有影响,我们可以将unlikely忽略。然后判断一下I/O操作是否越界即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static inline bool valid_io_request (struct zram *zram, sector_t start, unsigned int size) { u64 end, bound; if (unlikely(start & (ZRAM_SECTOR_PER_LOGICAL_BLOCK - 1 ))) return false ; if (unlikely(size & (ZRAM_LOGICAL_BLOCK_SIZE - 1 ))) return false ; end = start + (size >> SECTOR_SHIFT); bound = zram->disksize >> SECTOR_SHIFT; if (unlikely(start >= bound || end > bound || start > end)) return false ; return true ; }
__zram_make_request 如果valid_io_request判断I/O合法,驱动就会执行__zram_make_request函数来对I/O进行具体的处理。
接下来我们来具体看一下__zram_make_request的具体实现。首先index和offset用于定位zram磁盘中的位置,之前也讲到zram用一个table来描述每一页的元数据,这里index就是用于索引页的页号,而offset就是页内偏移。
考虑对I/O操作的处理方式,这里一共有三种可能的I/O操作,分别是丢弃、读和写。函数首先判断是否为丢弃discard I/O操作,如果是则调用zram_bio_discard函数进行处理。关于discard的概念可以看看这一篇blog:REQ_OP_DISCARD 。这里注意,对于discard类型的bio,没有也不需要bio_vec结构体。
如果I/O操作不是discard操作,则代码会遍历bio中的每一个bio_vec,根据bio_vec中描述的内存中的位置和长度以及index和offset索引的zram中的位置来不断进行I/O的读或写操作,对应zram_bvec_rw函数的调用,然后更新index和offset。关于bio_vec中具体字段的值,还请看我一开始提到的博客:通用块层 struct bio 详解 。下面给出代码注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 static void __zram_make_request(struct zram *zram, struct bio *bio){ int offset; u32 index; struct bio_vec bvec ; struct bvec_iter iter ; unsigned long start_time; index = bio->bi_iter.bi_sector >> SECTORS_PER_PAGE_SHIFT; offset = (bio->bi_iter.bi_sector & (SECTORS_PER_PAGE - 1 )) << SECTOR_SHIFT; switch (bio_op(bio)) { case REQ_OP_DISCARD: case REQ_OP_WRITE_ZEROES: zram_bio_discard(zram, index, offset, bio); bio_endio(bio); return ; default : break ; } start_time = bio_start_io_acct(bio); bio_for_each_segment(bvec, bio, iter) { struct bio_vec bv = unsigned int unwritten = bvec.bv_len; do { bv.bv_len = min_t (unsigned int , PAGE_SIZE - offset, unwritten); if (zram_bvec_rw(zram, &bv, index, offset, bio_op(bio), bio) < 0 ) { bio->bi_status = BLK_STS_IOERR; break ; } bv.bv_offset += bv.bv_len; unwritten -= bv.bv_len; update_position(&index, &offset, &bv); } while (unwritten); } bio_end_io_acct(bio, start_time); bio_endio(bio); }
zram_bio_discard 接下来我们先看zram_bio_discard这个函数,这里比较有意思的一个地方是如果offset不是0,即要清空的内容的起始地址在一个zram页的中间,按理来说应该先把当前这个zram页从mem_pool中取出来,然后把相应部分清零,之后再把这个页压缩并存回mem_pool中。但是这里对于这种情况zram选择直接skip掉这一部分空间的清空,而是从下一页的开头开始清空。清除操作也比较简单,遍历每一个待清除的页,先加锁,然后调用zram_free_page,最后解锁即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static void zram_bio_discard (struct zram *zram, u32 index, int offset, struct bio *bio) { size_t n = bio->bi_iter.bi_size; if (offset) { if (n <= (PAGE_SIZE - offset)) return ; n -= (PAGE_SIZE - offset); index++; } while (n >= PAGE_SIZE) { zram_slot_lock(zram, index); zram_free_page(zram, index); zram_slot_unlock(zram, index); atomic64_inc(&zram->stats.notify_free); index++; n -= PAGE_SIZE; } }
zram_free_page zram_free_page函数如下,根据zram结构体中的flag变量来判断当前页的类型,并清除flag中相应的位。这里,如果该页的ZRAM_WB置位,表示当前页被写回到一个磁盘中,然后调用free_block_bdev函数来释放磁盘中的页,但是linux 6.1版本中的free_block_bdev函数是个空函数,也许是不支持zram写回到磁盘?此外,对于ZRAM_SAME置位的页,该页的内容可以从table表中直接获得,不需要再存储到mem_pool中。在清除对应位之后,从table表中获得对应页在mem_pool中的handle,然后调用zs_free函数从mem_pool中释放该页即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 static void zram_free_page (struct zram *zram, size_t index) { unsigned long handle; #ifdef CONFIG_ZRAM_MEMORY_TRACKING zram->table[index].ac_time = 0 ; #endif if (zram_test_flag(zram, index, ZRAM_IDLE)) zram_clear_flag(zram, index, ZRAM_IDLE); if (zram_test_flag(zram, index, ZRAM_HUGE)) { zram_clear_flag(zram, index, ZRAM_HUGE); atomic64_dec(&zram->stats.huge_pages); } if (zram_test_flag(zram, index, ZRAM_WB)) { zram_clear_flag(zram, index, ZRAM_WB); free_block_bdev(zram, zram_get_element(zram, index)); goto out; } if (zram_test_flag(zram, index, ZRAM_SAME)) { zram_clear_flag(zram, index, ZRAM_SAME); atomic64_dec(&zram->stats.same_pages); goto out; } handle = zram_get_handle(zram, index); if (!handle) return ; zs_free(zram->mem_pool, handle); atomic64_sub(zram_get_obj_size(zram, index), &zram->stats.compr_data_size); out: atomic64_dec(&zram->stats.pages_stored); zram_set_handle(zram, index, 0 ); zram_set_obj_size(zram, index, 0 ); WARN_ON_ONCE(zram->table[index].flags & ~(1UL << ZRAM_LOCK | 1UL << ZRAM_UNDER_WB)); }
zram_bvec_rw 看完discard操作后,我们继续阅读zram I/O读写操作的代码,前边提到__zram_make_request函数对每一个小的bio_vec调用zram_bvec_rw函数执行I/O读写操作。zram_bvec_rw代码如下,可以看到,这个函数只是根据bio的操作类型来调用zram_bvec_read和zram_bvec_write函数。在I/O读操作后,调用了flush_dcache_page函数将读取出的页从dcache写回到内存中。在执行完读写操作后,调用zram_accessed函数将zram中被访问到的页的ZRAM_IDLE位清零。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static int zram_bvec_rw (struct zram *zram, struct bio_vec *bvec, u32 index, int offset, enum req_op op, struct bio *bio) { int ret; if (!op_is_write(op)) { atomic64_inc(&zram->stats.num_reads); ret = zram_bvec_read(zram, bvec, index, offset, bio); flush_dcache_page(bvec->bv_page); } else { atomic64_inc(&zram->stats.num_writes); ret = zram_bvec_write(zram, bvec, index, offset, bio); } zram_slot_lock(zram, index); zram_accessed(zram, index); zram_slot_unlock(zram, index); if (unlikely(ret < 0 )) { if (!op_is_write(op)) atomic64_inc(&zram->stats.failed_reads); else atomic64_inc(&zram->stats.failed_writes); } return ret; }
zram_bvec_read zram_bvec_read函数逻辑也较为简单,首先判断当前的bio_vec是否是对一整个页的读取,如果不是,则新申请一个临时页,先调用__zram_bvec_read函数将zram中一整个页读取到该临时页,再将临时页中bio_vec需要的一部分复制到bio_vec指示的相应位置处。
如果是对一整个页的读取,则直接调用__zram_bvec_read函数将zram中的页读取到bio_vec对应的内存页中即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static int zram_bvec_read (struct zram *zram, struct bio_vec *bvec, u32 index, int offset, struct bio *bio) { int ret; struct page *page ; page = bvec->bv_page; if (is_partial_io(bvec)) { page = alloc_page(GFP_NOIO|__GFP_HIGHMEM); if (!page) return -ENOMEM; } ret = __zram_bvec_read(zram, page, index, bio, is_partial_io(bvec)); if (unlikely(ret)) goto out; if (is_partial_io(bvec)) { void *src = kmap_atomic(page); memcpy_to_bvec(bvec, src + offset); kunmap_atomic(src); } out: if (is_partial_io(bvec)) __free_page(page); return ret; }
__zram_bvec_read I/O读操作的最后一个函数(读操作我想写的最后一个函数,代码太多了,先偷个懒),__zram_bvec_read首先要判断要zram中存储的页是否被写回到了磁盘中,如果被写回到了磁盘中,则zram调用read_from_bdev函数直接从磁盘将页读取到内存中的目标地址处。这里read_from_bdev函数的一个参数是zram_get_element(zram, index),这个参数就是table[index].element,代表了磁盘页的句柄。
如果没有被写回到磁盘,zram则判断该页的ZRAM_SAME位是否被置位,如果置位,表示这一页被相同的element填充,则zram可以很简单的从table[index].element获得页的填充内容element,使用这个element填充满一页即可。
最后一种情况,要读取的页存储在mem_pool中,则首先获得该页存储在mem_pool中的对象的大小,如果对象大小小于一页,表示该页被压缩过了,如果对象大小等于一页,则表示该页没有被压缩。首先调用zs_map_object函数把handle映射为一个src指针,这个指针就指向mem_pool中的一块区域,可以通过读这个指针来实现读mem_pool中的内容。然后根据上述对象大小的判断,如果大小为一页,直接将src指针处的内容copy到目标内存页即可;如果大小小于一页,则要先调用zcomp_decompress把src处的内容解压缩到目标内存页中。最后调用zs_unmap_object将handle和src指针的映射撤销掉即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 static int __zram_bvec_read(struct zram *zram, struct page *page, u32 index, struct bio *bio, bool partial_io) { struct zcomp_strm *zstrm ; unsigned long handle; unsigned int size; void *src, *dst; int ret; zram_slot_lock(zram, index); if (zram_test_flag(zram, index, ZRAM_WB)) { struct bio_vec bvec ; zram_slot_unlock(zram, index); if (!bio) return -EOPNOTSUPP; bvec.bv_page = page; bvec.bv_len = PAGE_SIZE; bvec.bv_offset = 0 ; return read_from_bdev(zram, &bvec, zram_get_element(zram, index), bio, partial_io); } handle = zram_get_handle(zram, index); if (!handle || zram_test_flag(zram, index, ZRAM_SAME)) { unsigned long value; void *mem; value = handle ? zram_get_element(zram, index) : 0 ; mem = kmap_atomic(page); zram_fill_page(mem, PAGE_SIZE, value); kunmap_atomic(mem); zram_slot_unlock(zram, index); return 0 ; } size = zram_get_obj_size(zram, index); if (size != PAGE_SIZE) zstrm = zcomp_stream_get(zram->comp); src = zs_map_object(zram->mem_pool, handle, ZS_MM_RO); if (size == PAGE_SIZE) { dst = kmap_atomic(page); memcpy (dst, src, PAGE_SIZE); kunmap_atomic(dst); ret = 0 ; } else { dst = kmap_atomic(page); ret = zcomp_decompress(zstrm, src, size, dst); kunmap_atomic(dst); zcomp_stream_put(zram->comp); } zs_unmap_object(zram->mem_pool, handle); zram_slot_unlock(zram, index); if (WARN_ON(ret)) pr_err("Decompression failed! err=%d, page=%u\n" , ret, index); return ret; }